《實操中的GPT-6:首日應關注哪些衡量指標,而非追逐規格參數》
當「GPT-6」終於能在你的使用環境中開放測試時,網路上將充斥著它的技術參數、各路熱議觀點和實測截圖。但其中絕大多數內容都無法幫你判斷是否值得切換到這個新版本。
唯一至關重要的實際問題是:它能否在你真實的約束條件下、以你實際的成本,提升你實際任務的完成成果?
截至2026年4月15日,你可透過即刻制定評估方案,為屆時做好準備。若想瞭解OpenAI發布重大版本的官方溝通慣例,可參閱《GPT-5.4發布介紹》;若需明確「模型應遵循的行為準則」,請參考《OpenAI模型規範》;若想瞭解可能影響版本部署及能力權限取得的風險界定框架,可參閱《就緒框架》。
四個能擊破所有謠言的數字
如果你第一天只能考量四件事,那就考量這四件:
首次嘗試可用性成功率
有多少比例的任務無需編輯即可使用?
2)最壞情況下的失效率
一旦出現故障,其嚴重程度如何,發生頻率又有多高?
3)約束符合率
它是否遵循格式模板、排版規範、語氣鎖定要求,以及「務必做到/嚴禁觸碰」的相關規則?
4)單位有效產出成本
並非按令牌核算成本——而是按可交付的成果核算成本。
這些量化指標將「新車型炒作噱頭」轉化為了索然無味的決策。
打造首日評估包
該評估包應體積小巧,執行耗時不超過兩小時,同時又足夠貼近實際,能反映真實狀況。
包含三種類型的任務
1) 每週任務(12–20)
你實際從事的工作:摘要、結構化輸出、腳本、改寫任務。
2)拆解類任務(3~5)
可暴露故障模式的任務:嚴格模式規範、模糊不清的指令、多步驟規劃。
3)長上下文任務(1–2)
一份包含諸多約束條件的正式專案簡報:涵蓋一份產品需求文件(PRD)、一套系列設定大全以及多鏡頭分鏡腳本方案。
進行多次試驗
每個任務需執行3至5次。單次表現優異但兩次表現不佳的模型,並不適用於高產量流水線的生產環境。
如何無需爭論就能快速得分
使用一套人類可以快速評分的簡單評分標準:
正確性(0–2分)
完整性(0–2)
格式合規性(0–2)
連貫性(0~2分)
安全與政策適配性(0–2)
然後新增兩項二進制檢查:
無需編輯即可使用(是/否)
今日出貨(是/否)
這能讓評估立足於實際。
自主智能體效能改進需衡量哪些指標
如果有傳言稱GPT-6具備更強的自主能力,那就去評估那些真正關鍵的行為表現:
它是否選擇了正確的步驟?
完成後會停止嗎?
若某一步驟失敗,它是否會恢復?
它是否遵守工具約束
自主智慧體的改進只有在可控的情況下才具有價值。
創作者應衡量的內容
創作者往往最先在規劃與連貫性層面察覺到可提升之處。測評:
腳本計時保真度(是否符合範本規範)
拍攝清單清晰性(是否可拍攝)
提示框架穩定性(是否保留特徵與風格)
跨鏡頭漂移(它會使角色發生變異嗎?)
隨後維持生產穩定,這樣就能將收益歸因於該規劃模型。達成此目標的簡單方法如下:
使用奈米香蕉2 AI影像產生器產生關鍵影格
用Kling 3激勵得獎者AI視頻生成器
妥善整理資產、版本與匯出項目,確保你的對比結果始終公平合理。
如果GPT-6優化了規劃能力,你無需更改生產工具,就能讓輸出結果變得更加一致。
規避遺憾的首日上線方案
即便GPT-6的評分更高,在首日就全面切換也是一個常見錯誤。更穩妥的上線方案:
1) 幕後影子測試
2) 試點低風險任務
3)拓展至中等風險產出
4)僅將其用於高風險自動化操作
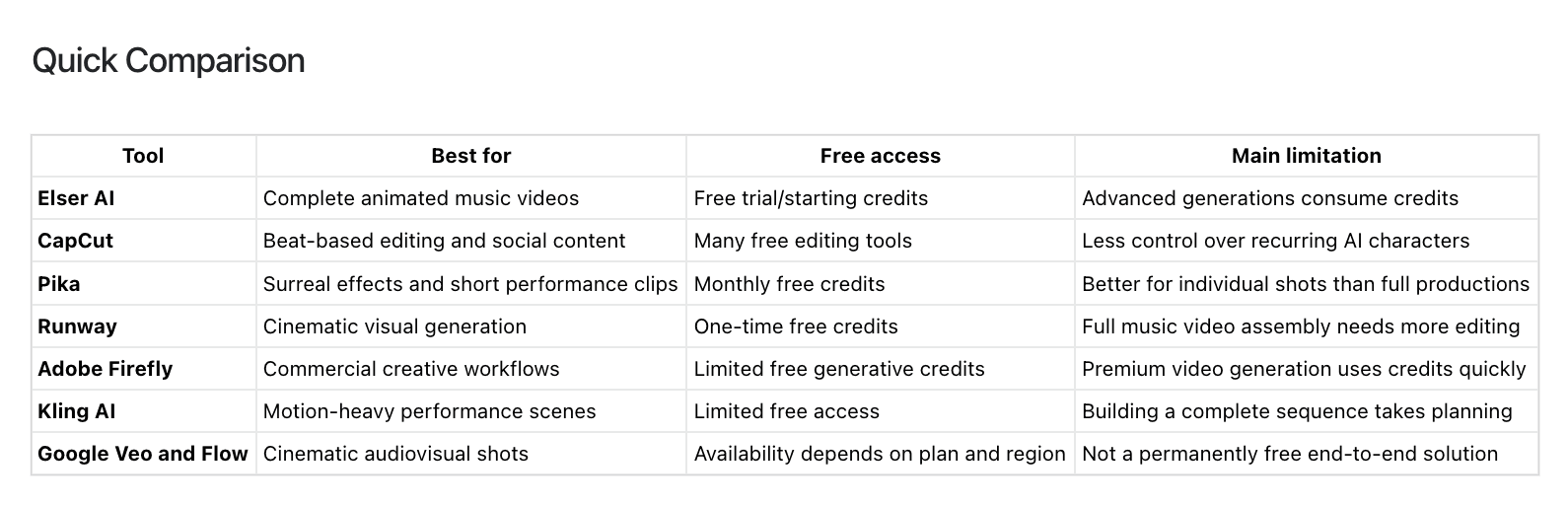
請保留備用模型,直至你完成了一段時間的穩定性驗證為止。對於團隊和創作者而言,將你的測試輸出、評分標準以及上線部署備註集中存放在同一個地方,也會很有幫助,例如Elser AI這樣你就能比對前後差異,且不會混淆各個版本。
常見問題解答
當GPT-6可使用時,我首先應該做什麼
在變更任何生產環境的預設設定之前,請先行執行評估套件。測試首次試用的易用性、執行差異以及合規約束。若您決定正式採用此方案,請先啟動試點專案,而非一次性全面切換。
為什麼一次就能上手的易用性比「最佳輸出效果」更為重要
因為生產部署是一場比拚規模的較量。如果每個任務都需要重試三次,你就會在時間、成本與精力上付出代價。一款性能稍遜色但始終穩定可用的模型,通常是更適合投產的選擇。
我該如何公正地衡量變異數呢?
以相同輸入重複執行多次,分別為每一輪執行評分,並比較最佳與最差的狀況。對於頻繁開展自動化作業或頻繁發布產品的團隊而言,變異數往往是決定性的參考因素。
什麼是合適的「升級觸發條件」
測試前設定觸發標準:例如首次嘗試可用性提升20%、最壞場景下故障率更低,且符合更高的規範要求。若模型未達到觸發標準,則將其視為試點候選方案,而非預設方案。
如果GPT-6效能更強但價格更貴呢?
計算每單位可用產出的成本,以此判斷哪些場景值得投入使用。許多團隊僅將性能最強的模型用於高價值任務,而以成本更低的模型處理日常工作。「『更優』並不總是在所有場景都物有所值。」
我應該如何評估安全性差異?
將風險敏感型任務納入您的工具包,並針對拒絕邊界與政策適配度進行評分。千萬不要將安全視為附註——發生安全倒退的代價可能相當高昂。若您在受規管領域推出產品,請要求採用階段性上線方案並強化監控。
如果創作者想要快速測試GPT-6,他們應該怎麼做?
使用固定腳本模板與固定鏡頭列表模板,隨後進行多次試驗。檢測其是否能降低生成飄移並優化提示架構。保持視覺生成工作流程固定不變,以便精準將改進效果歸因至相對應的影響因素。
我能依靠公開基準測試結果來做出首日決策嗎?
基準測試或許能勾起你的好奇心,但它們極少能符合你的實際限制條件。不妨將其做為參考起點,而非決策工具。你的自研評估套件,才是進行切換的唯一可靠依據。
首日評估需要多長時間?
首輪決策盡量控制在兩小時以內。如果評估耗時一周,你將無法跟上快速的版本發布節奏。先從小規模起步,僅當該模型確屬真正的升級時再擴展規模。