Die besten KI-Sprechcharakter-Generatoren für Mehrcharakter-Dialoge im Jahr 2026
Einen sprechenden KI-Charakter zu erstellen ist relativ unkompliziert. Geben Sie dem Tool ein Porträt, fügen Sie eine Tonspur hinzu und warten Sie, bis sich der Mund bewegt.
Eine glaubwürdige Konversation zwischen zwei oder mehr Charakteren zu erstellen, ist ein anderes Problem.
Der Generator muss wissen, wer spricht, das Gesicht und die Stimme jedes Charakters bewahren, die korrekten Mundbewegungen animieren, natürliche Reaktionen erzeugen und die Szene zwischen Kamerawechseln beibehalten. Wenn er einen dieser Punkte falsch macht, wirkt das Gespräch sofort künstlich.
Das ist der Grund, warum der beste KI-Sprechcharakter-Generator für Dialoge mit mehreren Charakteren nicht unbedingt das Tool mit dem beeindruckendesten Talking-Head-Demo ist. Es ist dasjenige, das Dialoge als eine Szene behandelt statt einer Folge von bewegten Mündern.
Für diesen Vergleich habe ich mich auf fünf praktische Anforderungen konzentriert:
- Eindeutige und wiederverwendbare Charakteridentitäten
- Getrennte Stimmen für jeden Sprecher
- Genaues Lippen-Sync
- Reaktionsaufnahmen und Leistungssteuerung
- Unterstützung für mehrfach aufgenommene oder storyboard-basierte Dialoge
Was macht KI-Dialoge glaubwürdig?
Guter Dialog ist nicht nur Rede. Es ist ein Austausch von Aufmerksamkeit.
Während ein Charakter redet, hört der andere zu. Sie wegschauen, reagieren, unterbrechen, zögern, lächeln oder werden unbehaglich. Diese stillen Reaktionen kommunizieren oft mehr als die gesprochene Zeile.
Eine überzeugende KI-Dialogszene benötigt daher vier Schichten.
Identität
Jede Person muss bei jeder Aufnahme das gleiche Gesicht, den gleichen Körper, die gleiche Kleidung, das gleiche Alter und den gleichen visuellen Stil beibehalten.
Stimme
Charakter A sollte nicht plötzlich die Sprechtonhöhe, das Sprechtempo, den Akzent oder die emotionale Darstellungsweise von Charakter B übernehmen.
Redereihenfolge
Nur der korrekte Mund sollte sich während jeder Zeile bewegen. Überlappende Sprache muss absichtlich sein.
Reaktion
Nicht-sprechende Charaktere sollten am Leben bleiben, ohne willkürliche oder ablenkende Bewegungen auszuführen.
Der letzte Punkt wird oft übersehen. Ein perfekt lippsyncronisierter Sprecher neben einem gefrorenen Zuhörer wirkt immer noch unnatürlich.
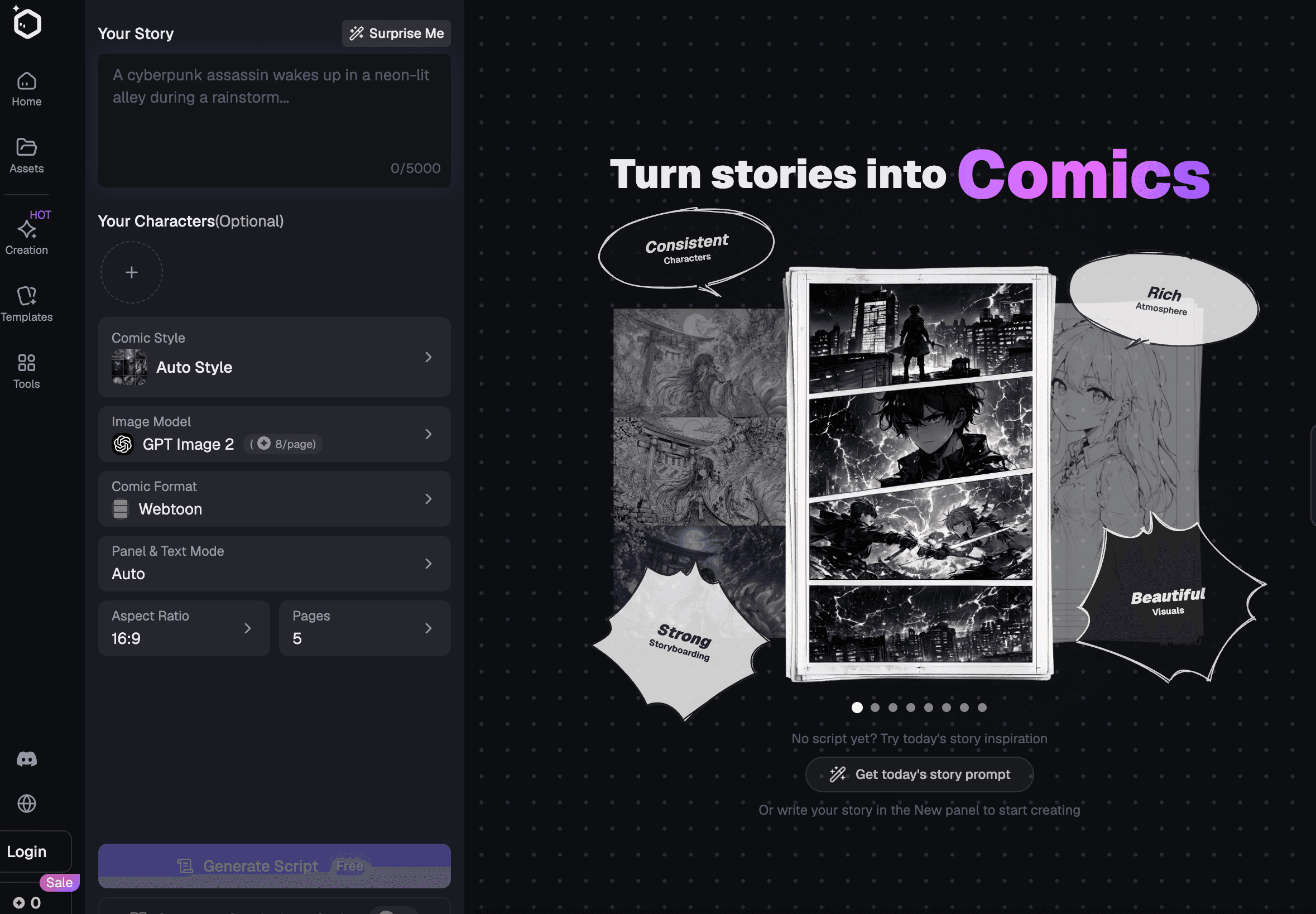
1. Elser AI: Bester insgesamt für animierte Geschichten mit mehreren Charakteren
Elser AI ist die stärkste insgesamt Wahl, wenn das Gespräch zu einer größeren animierten Geschichte gehört.
Die Plattform vereint die Erstellung von Originalcharaktern, Drehbüchern, Storyboards, KI-Videos, Sprachklonen, Musik, Soundeffekten und Lip-Sync. Statt mit einem anonymen Porträt zu beginnen, können Ersteller eine Besetzung zusammenstellen, visuelle Identitäten zuweisen, die Dialogabdeckung planen und diese Assets während der gesamten Produktion miteinander verbunden behalten.
Das ist wichtig, weil die meisten Dialogprobleme bereits vor dem Lip-Sync beginnen.
Wenn die Charaktere nicht klar definiert wurden, werden sie abschweifen. Wenn die Szene nicht storyboardet wurde, wirkt die Kameraabdeckung repetitiv. Wenn die Stimmen erst spät ausgewählt werden, passt das Timing möglicherweise nicht mehr zu den Aufnahmen.
Elser AI supports the wider production chain needed to solve those problems. Its audio tools allow creators to generate or clone voices, select emotional styles, adjust delivery speed, and make a character speak supplied text. (elser.ai)
Ein praktischer zweizeicheniger Arbeitsablauf
Stell dir vor, du erstellst eine kurze Szene zwischen Mina, einer impulsiven Lieferhexe, und Theo, einem nervösen Besitzer eines Cafés.
Beginnen Sie nicht mit einer Weitaufnahme und bitten Sie beide Charaktere, ein vollständiges Gespräch zu führen. Gestalten Sie die Szene wie herkömmliche Filmbildabdeckung:
1. Weite Zweieraufnahme, die beide Charaktere etabliert
2. Mittelnahe Einstellung von Mina, die spricht
3. Theos stille Reaktion
4. Nahaufnahme von Theo, der antwortet
5. Mina unterbricht
6. Zwei-Shot-Auflösung des Austauschs
Erstellen Sie separate Referenzprofile für Mina und Theo. Weisen Sie jedem eine stabile Stimme zu. Ordnen Sie dann den Dialogen bestimmten Storyboard-Panels zu.
Dies gibt dem System klare Informationen:
Welcher Charakter erscheint
Wer spricht
Was der Zuhörer tut
Welcher Kamerawinkel wird verwendet
- Wie lange die Warteschlange anhält
- Was unverändert bleiben muss
Warum Elser AI eine gute Passform ist
Elser AI ist besonders wertvoll für:
- Anime-Dialog
- Original-Charakter-Serie
- Animationskomödie
- Geschichtsgetriebene TikTok-Videos
- Virtuelle Schauspieler
Mehrsprachige animierte Szenen
- Wiederkehrende Besetzungen
- Dialoge gemischt mit Action, Musik oder Effekten
Es ermöglicht Erstellern außerdem, verschiedene Videomodelle auszuwählen, wenn eine Szene eine spezialisierte Fähigkeit benötigt. Kling kann einen komplexen Moment mit mehreren Sprechern bewältigen, während ein anderes Modell möglicherweise besser für eine stille Reaktion oder eine atmosphärische Einstellungsaufnahme geeignet ist.
Du kannst dich bei Elser AI registrieren und einen einfachen acht- bis zwölfssekündigen Austausch testen, bevor du eine längere Unterhaltung führst.
Fazit: Am besten für Kreative, die konsistente Charaktere, Stimmen, Storyboards, Animationen und Lip-Sync in einem einzigen Projekt benötigen.
2. Kling 3.0: Am besten geeignet für nativen Mehrcharakterdialog
Kling 3.0 ist eines der fähigsten aktuellen Modelle zur Generierung von Dialogen als Teil einer filmischen Sequenz.
Seine offizielle Dokumentation ermöglicht es Erstellern, Charakteren ihren jeweiligen Zeilen zuzuordnen, während Kuaishou angibt, dass Kling 3.0 komplexe Konversationen mit mehreren Charakteren und kontrollierter Sprechreihenfolge generieren kann. Es unterstützt zudem mehrere Sprachen, Akzente und Dialekte. (app.klingai.com)
Dies schafft Möglichkeiten, die mit früheren Modellen schwierig waren:
- Zwei Charaktere, die verschiedene Sprachen sprechen
- Wechselaufnahme-Gespräche
- Stimmenüberlagerung in Kombination mit sichtbarem Dialog
- Multi-Shot-Szenen mit nativem Ton
- Eindeutige Stimmen, die wiederkehrenden Charakteren zugewiesen werden
- Dialoge eingebettet in der Handlung
Kling versteht also filmische Anweisungen. Du kannst die Eingabeaufforderung wie ein kleines Drehbuch organisieren:
WEITWINKELAUFNAHME:
Mina betritt das leere Café und trägt ein nasses Paket. Theo schaut von hinter der Theke her hoch.
NAHERAUFNAHME AUF MINA:
Mina sagt, leicht atemlos, „Bitte sag mir, dass dies Nummer siebenundzwanzig ist.“
REAKTIONSAUFNAHME MIT THEO
Theo schaut auf die kaputte Nummer über der Tür und antwortet: „Es war früher so.“
Halte Mina und Theo visuell konsistent. Nur der aktive Sprecher bewegt seinen Mund.
Leiser Regen draußen, sanfter Raumton, zurückhaltende Anime-Performance.
Das ist viel verständlicher als die gesamte Unterhaltung in einem Absatz zu platzieren.
Wo Kling Zurückhaltung braucht
Nativer Dialog mit mehreren Charakteren ist mächtig, aber er entfernt keine Produktionsgrenzen.
Das Risiko steigt, wenn die Szene Folgendes enthält:
- Drei oder mehr sichtbare Lautsprecher
- Schnelle Unterbrechungen
- Körperlicher Kontakt während des Sprechens
Mehrere Kamerabewegungen
- Lange Zeilen
- Detaillierte Requisiten
- Charaktere, die sich einander vorbeikreuzen
Wenn ein Gespräch wichtig ist, teile es in handhabbare Einstellungen auf. Erzeuge die Einstellungsabdeckung, dann bearbeite die Sequenz. Eine traditionelle Shot-Reverse-Shot-Struktur mag zwar weniger technisch beeindruckend wirken, aber es ist weit wahrscheinlicher, dass sie funktioniert.
Kling 3.0 Ist im umfassenderen Arbeitsablauf von Elser AI verfügbar, wodurch Ersteller Charakterverweise und Dialogpläne vor der Generierung der Szene vorbereiten können. (The Complete Creator's ...)
Fazit: Bestes Modell für native audiovisuelle Unterhaltungen und mehrturnige Dialoge, wenn die Eingabeaufforderung sorgfältig strukturiert ist.
3. Laufsteg Akt Zwei: Am besten für die Inszenierung der Performance
Runway verfolgt einen eher leistungsorientierten Ansatz.
Act-Two nutzt ein Video einer Schauspielerleistung und eine Charakterreferenz. Das Modell überträgt Sprache, Gesichtsausdrücke und Gesten des Schauspielers auf den ausgewählten Charakter. Dies gibt Erstellern die direkte Kontrolle darüber, wie eine Zeile vorgetragen wird. (help.runwayml.com)
Für ein Gespräch zeichne jede Rolle separat auf.
Spielen Sie die Dialoge von Charakter A ein und lassen Sie dabei Pausen für Charakter B. Nehmen Sie dann die entsprechende Darstellung von Charakter B auf. Ordnen Sie jede Darstellung ihrem jeweiligen Charakter zu und fügen Sie die Aufnahmen im Schnitt zusammen.
Runway dokumentiert einen ähnlichen Vorgang zum Aufbau von Gesprächen mit zwei oder mehr Charakteren. Act-Two selbst akzeptiert eine einzelne Charaktereingabe, aber separate Durchgänge können zu einer Mehrcharakter-Szene kombiniert werden. (help.runwayml.com)
Warum diese Methode funktioniert
Ein Text-Prompt kann Emotion beschreiben, aber eine Performance demonstriert sie.
Vergleichen:
Theo spricht nervös.
Mit einer tatsächlichen Fahrleistung kannst du zeigen:
- Seine Augen weichen Mina aus
- Seine Schultern spannen sich an
Eine Pause vor dem letzten Wort
- Ein peinliches halbes Lächeln
- Seine Hände blieben nah bei seinem Körper
Diese Details machen die Schauspielerei spezifisch.
Beste Anwendungsfälle
Runway ist besonders stark für:
- Emotionaler Dialog
- Stilisierte Schauspielweise
- Komik-Timing
- Charaktermonologe
- Präsentatorenauftritte
- Szenen, die kontrollierte Gesten erfordern
- Mensch-zu-Charakter-Bewegungsübertragung
Der Kompromiss ist der Arbeitsaufwand. Jede Rolle erfordert möglicherweise eine separate Leistung und Generierung. Dies dauert länger als die native Generierung mehrerer Zeichen, bietet aber mehr Regiekontrolle.
Fazit: Am besten, wenn die Handlungsqualität wichtiger ist als die Ein-Klick-Bequemlichkeit.
4. HeyGen: Am besten für mehrsprachige Präsentatoren
HeyGen ist optimiert für Avatar-Präsentationen, Videotranslation, Sprachklonierung und mehrsprachige Lokalisierung.
Es unterstützt die Videotranslation in mehr als 175 Sprachen, mithilfe von Sprach- und Lippen-Synchronisationstechnologie, die dafür sorgt, dass übersetzte Sprecher natürlich wirken. Ersteller können mit vorhandenem Filmmaterial, Avataren oder sprechenden Fotos arbeiten. (heygen.com)
HeyGen ist nützlich für Dialog-Formate wie:
- Zweipersonen-Erklärungen
- Internationale Trainingsvideos
- Interview-Simulationen
- Bildungsgespräche
- Kundenservice-Demonstrationen
- Verkaufsrollenspiel
- Mehrsprachige Vortragende
Ihre echte Stärke ist die Lokalisierung. Ein Team kann ein Gespräch erstellen, die Sprecher übersetzen und es für mehrere Märkte anpassen, ohne jede Version neu aufzunehmen.
Jedoch ist dies ein anderes Produktionsproblem als die Erstellung einer filmischen Anime-Szene. HeyGen ist am stärksten, wenn Sprecher den Zuschauer ansprechen oder in einem kontrollierten Präsentationsformat interagieren. Es konzentriert sich weniger auf komplexe Umgebungen, Anime-Action, wiederkehrende Erzählungsorte oder durch Storyboards geleitete Dramatik.
Fazit: Am besten für mehrsprachige Präsentationsinhalte und lokalisierte Geschäftsgespräche.
5. Sync Labs: Am besten für vorhandenes Filmmaterial und Produktions-APIs
Sync Labs ist spezialisiert auf visuelle Synchronisation und Lippensynchronisation.
Sein System akzeptiert Video- oder Bildeingänge mit Audio oder Text und generiert anschließend neue Mundbewegungen, die zur Zielrede passen. Es bietet mehrere Modelle für unterschiedliche Anforderungen an Geschwindigkeit und Qualität sowie produktionsreife APIs und offizielle SDKs. (sync. labs)
Das macht es ideal, wenn die Szene bereits existiert.
Beispielsweise können Sie Folgendes haben:
- Ein abgeschlossenes animiertes Gespräch, dessen Dialoge neu verfasst werden müssen
- Eine Filmszene, die einer Lokalisierung bedarf
- Eine Werbung mit mehreren Sprachvarianten
- Charakteraufnahmen, die auf endgültige Stimmen warten
- Eine hochvolumige Anwendung, die automatisch sprechende Videos erstellt
Sync Labs erstellt nicht die gesamte Mehrfachcharakter-Szene für dich. Es löst ein spezifischeres Problem mit professioneller Tiefe: Es verändert, was ein vorhandener Charakter zu sagen scheint.
Seine Integrationen mit Adobe Premiere, ComfyUI, ElevenLabs, Python und TypeScript machen es besonders attraktiv für Studios und Entwickler. (sync.so)
Fazit: Am besten für professionelles Dubbing, Lokalisierung und automatisierte Produktionspipelines.
6. Hedra: Am besten für audio-getriebene Charakterdarstellungen
Hedra erstellt Videos mit sprechenden Charakteren aus einem Bild und einer Audiospur. Sein System zur Auswahl des Sprechers kann erkennen, welcher Charakter in einem Mehrpersonenbild sprechen soll, sodass Ersteller die Darbietung auf ein ausgewähltes Thema ausrichten können. (hedra.com)
Hedra eignet sich gut für:
Illustrierte Podcasts
- Charakterinterviews
- Erzählung in Langform
- Virtuelle Hosts
- Singende Porträts
- Audio-erstes soziales Content
Es ist am zuverlässigsten, wenn jeweils nur ein sichtbarer Charakter spricht. Du kannst dennoch ein Gespräch gestalten, indem du jeden Sprecher separat generierst und die Ergebnisse kombinierst.
Hedra ist weniger geeignet, wenn die Szene umfangreiche Bewegungen, komplexe Kamerabedeckung oder mehrere wiederkehrende Umgebungen erfordert. Betrachten Sie es eher als ein starkes Tool für die Charakterdarstellung statt als vollständiges Animationsstudio.
Fazit: Am besten geeignet für längere Audio-zentrierte Charaktervideos mit kontrollierter Auswahl der Sprecher.
7. CapCut: Am besten für schnelle soziale Gespräche
CapCut bietet zugängliche Lip-Sync-Funktionen, Audiobearbeitung, Untertitel, Zeitleisten, Effekte und soziale Exporte.
Es ist nützlich, wenn Sie bereits Charakter-Clips haben und eine schnelle Konversation für TikTok, Reels oder Shorts zusammenstellen müssen. Seine Lip-Sync-Tools können mit Menschen, Avataren und anderen Charakteraufnahmen arbeiten, während der Editor das Anordnen abwechselnder Redner einfach macht. (capcut.com)
CapCut ist bestens geeignet für:
Kurze komische Wortwechsel
- Memedialog
Soziales Geschichtenerzählen
- Beschriftungsreiche Gespräche
- Schnelles Dubbing
- Endgültige Bearbeitung von generierten Szenen
Es bietet nicht die gleiche projektweite Charakterverwaltung wie Elser AI oder die gleiche native Dialoggenerierung wie Kling. Seine Rolle liegt normalerweise gegen Ende der Produktion.
Fazit: Am besten als schneller Editor und Umfeld zum Fertigstellen von kurzen Dialogen.
Wie man eine bessere Dialogszene mit mehreren Charakteren erstellt
Jeden Zeichen unabhängig sperren
Erstellen Sie für jeden Sprecher ein separates Referenzpaket. Vermeiden Sie Referenzen, in denen Zeichen überlappen.
Stimmen vor der Animation zuweisen
Wählen Sie Stimme, Geschwindigkeit, emotionalen Ton und Akzent früh. Diese Entscheidungen bestimmen die Dauer der Einstellungen.
Sprecherbezeichnungen verwenden
Nennen Sie die Charaktere ausdrücklich:
MINA: "Du hast das Paket geöffnet?"
THEO: „Ich dachte, es wäre Kaffee.“
Verlasse dich nicht auf „das Mädchen“ und „den Mann“, sobald die Szene kompliziert wird.
Geben Sie den Hörern eine Aktion
Während ein anderer Charakter spricht, könnte der Zuhörer:
- Schau zum Redner
- Natürlich blinzeln
- Senke ihre Augen
- Die Arme verschränken
- Reagiere subtil
Bleiben Sie größtenteils still
Vermeide willkürliche dramatische Gesten.
Verwenden Sie herkömmliche Filmabdeckung
Weitaufnahme, Nahaufnahme des Sprechers, Reaktion, Antwort und Auflösung bleiben effektiv, da sie visuelle Informationen deutlich machen.
Sorgfältig mit Prozessüberlappungen umgehen
Bei Unterbrechungen zunächst saubere einzelne Auftritte erstellen. Überlappen Sie diese während der Bearbeitung, statt den Generator zu bitten, mehrere simultane Stimmen zu improvisieren.
Raumton beibehalten
Konsistente Umgebungsgeräusche helfen, dass separat erstellte Aufnahmen wie ein einziges Gespräch wirken.
Endgültiges Urteil
Kling 3.0 ist die leistungsfähigste Option zum Erstellen nativer audiovisueller Dialoge mit mehreren Charakteren in einer kontrollierten Abfolge. Runway Act-Two ist leistungsfähiger, wenn Sie jeden Gesichtsausdruck und jede Geste steuern möchten. HeyGen ist führend bei der Lokalisierung von Präsentatoren, Sync Labs bei professioneller Synchronisation, Hedra bei audiogetriebenen Charakterdarstellungen, und CapCut bei schneller Social-Media-Bearbeitung.
Für Kreatoren, die animierte Geschichten produzieren, Elser AI ist der beste Arbeitsablauf insgesamt, weil die Konversation mit persistenten Charakteren und einem Storyboard beginnen, über die Videogenerierung und die Stimmerstellung fortsetzen und mit Lippen-Synchronisation, Musik und Soundeffekten abschließen kann.
Eine glaubwürdige Unterhaltung entsteht nicht dadurch, dass man zwei Münder synchronisiert. Sondern dadurch, dass man zwei Charakteren etwas zu wünschen, etwas zu verbergen und genügend Bildschirmzeit zum Reagieren gibt.
Erstellen Sie Ihre nächste animierte Dialogszene mit Elser AI.