2026年最佳多角色对话AI语音角色生成器
创建一个会说话的AI角色相对简单。给该工具上传一张肖像,添加一段音轨,然后等待角色嘴巴动起来即可。
在两个或更多角色之间创作出真实可信的对话,是另一个不同的问题。
该生成系统必须明确发言者身份,保留每位角色的面部特征与声音,生成准确的口型动画,做出自然的反应,并在镜头切换时保持场景环境一致。只要任何一个环节出现失误,这段对话就会立刻显得虚假生硬。
这就是为何用于多角色对话的最佳AI会说话角色生成器,未必是拥有最惊艳虚拟头像说话演示的工具。真正出色的那款生成器,会将对话视作一个场景,而非一连串仅嘴巴活动的画面。
在本次对比中,我重点关注了五项实际需求:
- 独特且可复用的角色身份
- 为每位发言者提供独立的语音声道
精准唇形同步
- 反应镜头与表演控制
- 支持多镜头或基于分镜的对话
是什么让AI对话显得真实可信?
好的对话不仅仅是言语。它是注意力的交换。
当一名角色说话时,另一名角色在聆听。他们会移开视线、做出反应、打断对话、犹豫、微笑,或是感到局促不安。这些无声的回应往往比口头台词更能传递更多内容。
因此,一个令人信服的AI对话场景需要四个层级。
身份
每个人在所有镜头中都必须保持相同的面容、身形、服装、年龄和视觉风格。
语音
角色A不应突然继承角色B的音调、语速、口音或情感表达方式。
发言顺序
每一段台词都只能由对应的正确嘴部做出动作。 口型重叠的情况必须是刻意设计的。
反应
无台词角色应保持存活,且不得做出随意或分散注意力的动作。
最后一点常常被忽视。 口型完全同步的讲话者站在僵住的听众身旁,看起来依然很不自然。
1. Elser AI:制作多角色动画故事的综合最佳选择
Elser AI当这段对话隶属于一个更宏大的动画故事时,这是整体上的最佳选择。
该平台整合了原创角色创作、剧本、分镜、AI视频、语音克隆、音乐、音效和唇形同步功能。无需从匿名肖像开启创作,创作者可以搭建演员阵容、设定视觉形象、规划对话镜头覆盖范围,并在整个制作过程中保持这些素材的关联性。
这一点很重要,因为大多数台词的口型同步问题往往在唇形同步之前就已出现。
如果角色未被清晰塑造,人物形象就会模糊涣散。如果未提前绘制分镜,镜头拍摄就会显得重复乏味。如果延后挑选配音演员,台词节奏可能就无法适配镜头画面。
实用的双字符工作流
假设你正在编写一段发生在冲动配送女巫米娜和紧张兮兮的咖啡馆店主西奥之间的短篇场景。
不要以单个全景镜头开场,也不要让两名角色进行完整的对话。请按照常规的电影镜头调度来构建这场戏:
1. 双人宽镜头,同时交代两名角色
2. 米娜讲话的中近景
3. 西奥的沉默反应
4. 西奥回复的特写镜头
5. 米娜打断
6. 双镜头解决兑换问题
为米娜和西奥分别创建独立的参考配置文件,为每位角色分配一个稳定的语音,随后将对话映射至特定的分镜面板中。
这为该系统提供了明确的信息:
- 哪个角色出现了
- 谁在说话?
- 听众所做之事
使用的是哪个摄像机角度?
- 队伍会持续多久
- 必须保持不变的内容
为什么Elser AI非常适合
Elser AI 尤其适用于:
- 动漫台词
- 原创角色系列
动画喜剧
- 故事驱动型TikTok视频
- 虚拟演员
- 多语言动画场景
- 常驻演员阵容
- 对白与动作、音乐或音效相融合
当某个场景需要特定专业能力时,它还允许创作者选择不同的视频模型。Kling可以处理复杂的多发言人场景,而另一个模型或许更适合用于安静的反应镜头或是烘托氛围的环境定场镜头。
您可以注册Elser AI,在创建更长的对话之前,先体验一段时长8至12秒的简单交流。
评测结论:最适合需要在单个项目中实现风格统一的角色、配音、分镜、动画以及口型同步的创作者。
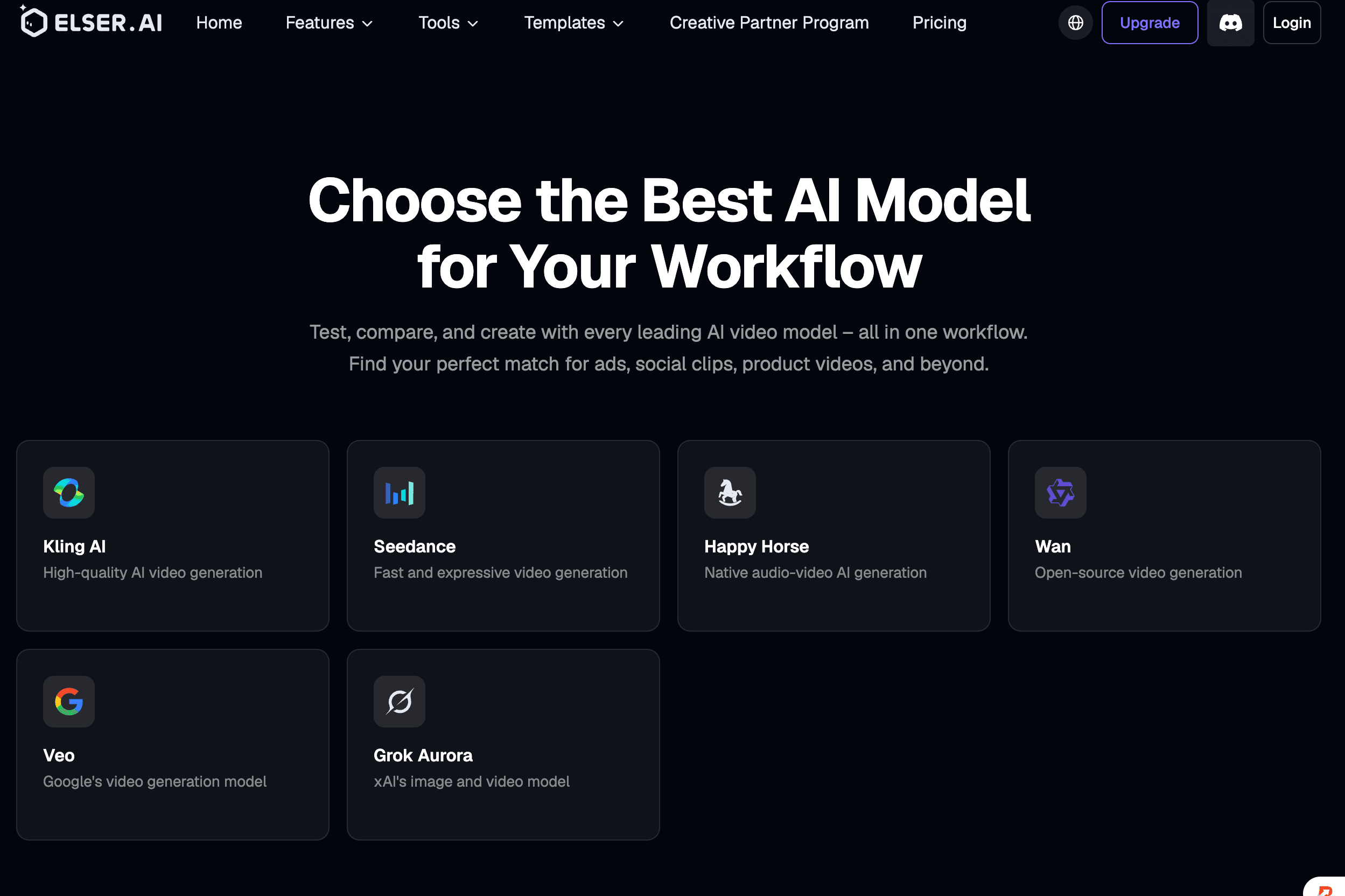
2. Kling 3.0: 最适合原生多角色对话
Kling 3.0 是目前最出色的可用于生成电影镜头序列中对话内容的模型之一。
其官方文档允许创作者将角色与其对应的台词相关联,而快手表示,Kling 3.0 能够生成带有可控发言顺序的复杂多角色对话。它还支持多种语言、口音和方言。(app.klingai.com)
这创造出了早期模型难以实现的可能性:
- 两个说着不同语言的角色
- 正反打镜头对话
- 旁白与可见对话结合
- 带有原生音效的多镜头场景
- 为反复出现的角色分配独特的配音
- 嵌入动作中的对话
Kling 同样支持影视化指令。你可以将提示词编排为一部微型剧本的格式:
全景镜头:
米娜拿着一个湿漉漉的包裹走进空荡荡的咖啡馆。 西奥从柜台后面抬起头来。
米娜特写:
米娜微微喘着气说道:“请告诉我这是第二十七个。”
西奥的反应镜头:
西奥瞥了一眼门上那个破损的门牌号,回答道:“以前是这样的。”
保持米娜和西奥的视觉一致性。仅当前发言者的嘴巴会动。
窗外静谧的雨,柔和的室内环境音,克制内敛的动画演绎。
这比把整段对话放在同一段落里要清晰得多。
克林需要克制之处
原生多角色对话功能强大,但它并不能消除制作限制。
当场景中包含以下内容时,风险会升高:
- 三名或更多可见的发言者
- 快速中断
- 演讲时的肢体接触
- 多个镜头移动
- 长队
- 详细属性
- 角色在彼此前方交错
当一段对话至关重要时,将其拆分为易于把控的镜头。先完成覆盖拍摄,再剪辑镜头序列。传统的正反打镜头结构或许看起来没那么有科技冲击力,但却更有可能获得成功。
Kling 3.0 可在Elser AI的更广泛工作流程中使用,让创作者能够在生成场景前准备好角色参考资料与对话规划方案。(《创作者完全指南……》)
结论:在提示词经过精心构建的情况下,该模型是原生音视频对话与多轮对话的最佳选择。
3. 秀场第二幕:最适合指导演出
Runway 采用了更以性能为导向的方法。
Act-Two 采用一段演员表演驱动视频与角色参考素材。该模型能够将演员的语音、面部表情和手势迁移到选定的角色身上。这让创作者可以直接掌控台词的演绎方式。(help.runwayml.com)
进行对话时,请分别记录每个角色的内容。
演绎角色A的台词,同时为角色B留出停顿间隙。随后录制角色B的对应表演。将每份表演匹配至对应的角色设定,并在剪辑阶段完成镜头拼接。
Runway 记录了与两名或更多角色构建对话的类似流程。Act-Two 本身仅接受单个角色输入,但可将多次独立处理合并为多角色场景。(help.runwayml.com)
为什么这个方法有效
文字提示可以描述情感,但表演却能展现它。
比较:
西奥紧张地说话。
凭借真实的驾驶表现,你可以展示:
- 他的目光避开了米娜
- 他的肩膀紧绷着
- 在最后一个单词前停顿一下
一个尴尬的半微笑
- 他的双手一直贴近身体
这些细节让表演显得十分具体。
最佳应用场景
Runway 尤其擅长以下方面:
情感对话
风格化表演
- 喜剧时机
- 角色独白
- 主持人表现
- 需要受控手势的场景
- 真人到角色的动作迁移
权衡之处在于工作量。每个角色可能需要单独的表演和生成环节。这比原生多角色生成耗时更长,但能提供更直接的导演把控权。
评定结论:当操作质量比一键便捷性更重要时,此为最佳选择。
4. HeyGen:最适合多语言演讲者
HeyGen 专为头像演示、视频翻译、语音克隆和多语言本地化优化。
它支持将视频翻译成超过175种语言,其搭载的语音和唇形同步技术旨在让译制后的说话者显得自然真实。创作者可使用现有视频素材、虚拟形象或会说话的照片进行创作。(heygen.com)
HeyGen 适用于对话式格式,例如:
- 双人解说内容
- 国际培训视频
- 面试模拟
- 教育对话
- 客户服务演示
- 销售角色扮演
- 多语言演讲嘉宾
它真正的优势在于本地化。团队只需创建一段对话,对发言者的台词进行翻译,即可针对多个市场进行适配,无需为每个版本重新录音。
不过,这与制作具有电影质感的动画场景是截然不同的制作难题。当演讲者面向观众发言,或是以受控的演示格式进行互动时,HeyGen的表现最为出色。它并不擅长处理复杂的环境、动画动作戏份、反复出现的叙事场景,或是以分镜主导的戏剧化内容。
评测结论:最适合多语言演示文稿内容及本地化商务对话。
5. Sync Labs: 最适合现有影视素材与影视制作API
Sync Labs 专注于视觉配音以及唇形同步。
该系统可接收带有音频或文本的视频及图像输入,随后生成与目标语音匹配的全新口部动作。它针对不同的速度与质量需求提供了多款模型,同时附带生产级API与官方SDK。(sync. labs)
当场景已存在时,这使其成为理想之选。
例如,你可能会有:
- 一段已完成的动画对话,需重写对白
- 需要本地化的电影场景
- 一个包含多种语言版本的广告
- 角色视频素材等待最终配音
- 一款可自动生成口播视频的高批量应用程序
Sync Labs 不会为你创建完整的多角色场景。它能解决兼具专业深度的细分问题:修改现有角色的台词内容。
它与Adobe Premiere、ComfyUI、ElevenLabs、Python和TypeScript的集成使其对工作室和开发者尤其具有吸引力。(sync.so)
评测结论:最适合专业配音、本地化以及自动化制作流程。
6. Hedra:最适合音频驱动的角色表演
Hedra可通过单张图片和音频轨道制作会说话的角色视频。它的说话者选择系统可以识别多人图片中的哪个角色应当开口说话,让创作者能够将表演导向选定的主体。(hedra.com)
Hedra 适用于:
- 带插图的播客
- 角色访谈
- 长篇叙事
- 虚拟主机
- 歌唱肖像
音频优先的社交内容
当每次仅有一位可见角色发言时,效果最为可靠。 你仍可以通过分别生成每位发言者的内容并将结果合并,来构建对话。
Hedra在场景需要大量移动镜头、复杂的镜头调度或是多个重复出现的环境时,不太适用。可以将其视为一款出色的角色表演工具,而非完整的动画制作工作室。
评定结论:最适合用于制作发言人选择可控的长时长音频主导型角色视频。
7. 剪映:最佳快速社交对话工具
CapCut 提供易用的唇同步、音频编辑、字幕、时间轴、特效及社交平台导出功能。
当你已经拥有角色片段,需要为TikTok、Reels或Shorts快速拼接一段对话时,它非常实用。它的口型同步工具可用于真人、虚拟形象及其他角色素材,而编辑器能让你轻松安排交替发言的角色。(capcut.com)
剪映非常适合用于:
- 简短喜剧互动
- 梗对话
社交叙事
- 字幕密集型对话
快速配音
- 已生成场景的最终编辑
它无法提供与Elser AI同等的项目级角色管理功能,也无法提供与Kling同等的原生对话生成能力。它通常在制作流程的后期阶段发挥作用。
结论:最适合作为短篇对话的快速编辑及后期制作环境。
如何打造更出色的多角色对话场景
独立锁定每个字符
为每位说话者创建一个独立的参考素材包。避免出现角色重叠的参考素材。
在动画制作前分配配音
尽早选择音色、语速、情绪基调与口音。 这些选择将决定镜头时长。
使用说话人标签
明确列出角色名称:
米娜:“你拆开包裹了?”
西奥:“我还以为那是咖啡呢。”
一旦场景变得复杂,就不要依赖“女孩”和“男人”。
给听众一个行动指引
当另一个角色说话时,听众可能会:
- 看向说话者
自然眨眼
- 垂下他们的双眼
- 交叉双臂
- 微妙地做出反应
- 尽量保持静止
避免随意的夸张手势。
使用常规胶片覆盖
全景镜头、发言者特写、反应镜头、应答镜头以及解决镜头依然十分有效,因为它们能让视觉信息清晰明了。
仔细处理重叠部分
如需处理语音中断相关情况,请先创建清晰的单段独立语音表演。在编辑阶段将它们重叠,而非让生成器即兴生成多个同步语音。
保留房间环境音
连贯一致的环境音能让分别拍摄的镜头看起来如同同一段对话。
最终裁决
Kling 3.0 是在可控序列中生成本土化多角色视听对话的最佳选择。当你想要把控每一个面部表情和肢体动作时,Runway Act-Two的表现更为出色。HeyGen 在主持人本地化领域处于领先地位,Sync Labs 专精专业配音,Hedra 擅长音频驱动的角色表演,CapCut 则在快速社交内容剪辑方面更具优势。
对于制作动画故事的创作者们, Elser AI这是最佳的整体工作流程,可先以常驻角色和故事板开启对话,随后依次完成视频生成、语音创作,最后添加唇同步效果、音乐及音效。
一段真实可信的对话,绝非靠同步两张嘴就能打造出来。它的诞生,是赋予两个角色各自的所求、暗藏的心事,再配上足够的镜头时长让他们做出反应。