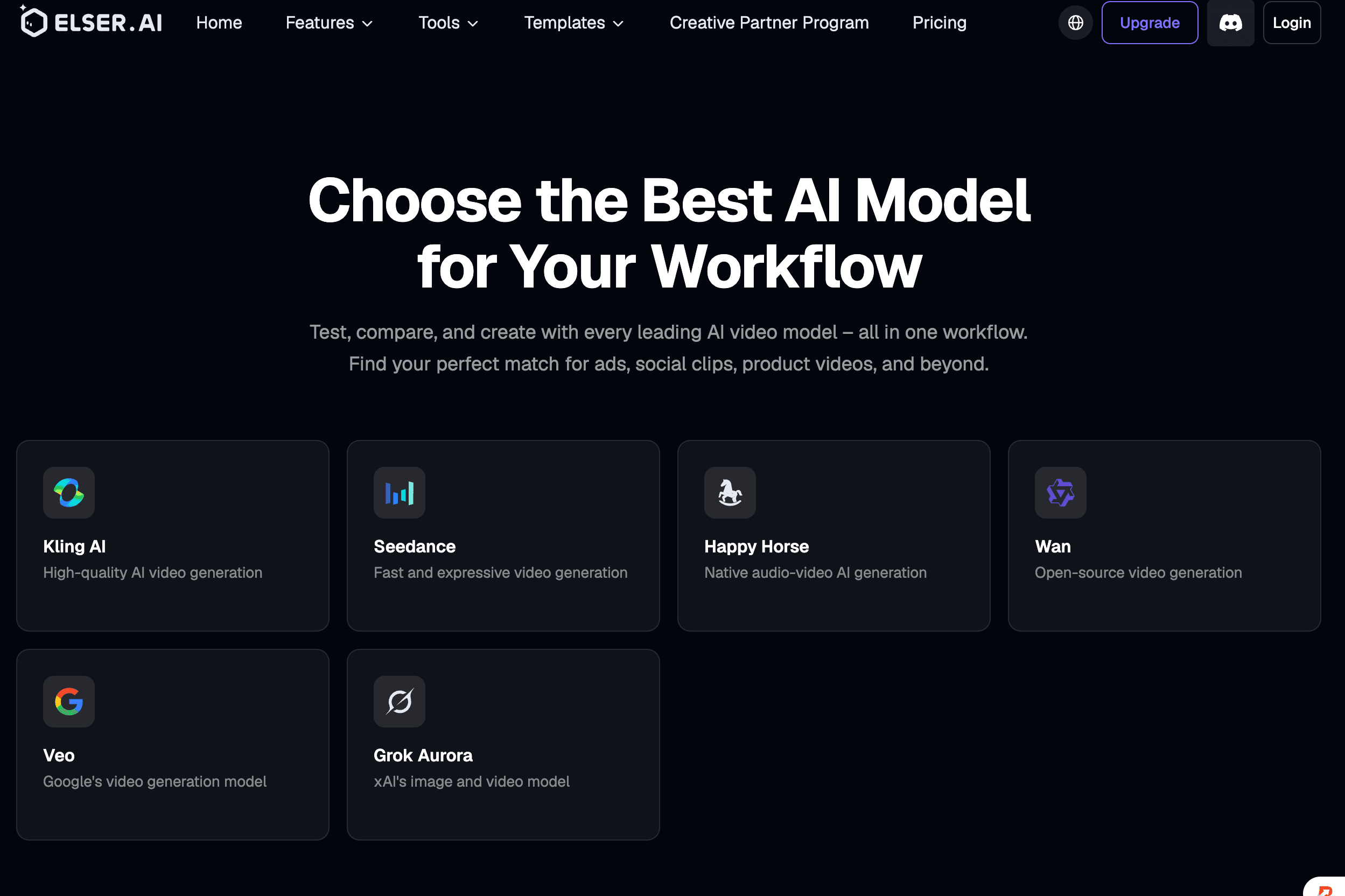
HappyHorse 或 Seedance 2.0:哪個AI模型更出色?
HappyHorse與Seedance 2.0常被相提並論,但二者的亮點各有不同。HappyHorse被視為業界標竿與優質案例,而Seedance 2.0則圍繞多模態影片創作建構了更清晰的面向大眾的產品敘事邏輯。
對大多數創作者來說,正確的問題並非哪種模型更具病毒式傳播效果,而是哪一種更易於讓人信賴、便於測試,且能融入實際工作流程。
如果您更希望在測試新版本的同時,保持週邊的創意技術棧穩定, Elser AI工作流是更安全的錨點。
快速裁決
如果你正在糾結選擇HappyHorse還是Seedance 2.0,不妨拆解一下兩者各自的優勢所在。HappyHorse以其出色的排行榜增長勢頭而聞名,而Seedance 2.0則提供了更為清晰規範的官方多模態工作流。
從文件層面來看,HappyHorse的公開資料略顯零散,而Seedance 2.0則獲得了字節跳動更直接的官方支持。
兩款模型在基準測試中都表現出色:HappyHorse的成績十分亮眼,而Seedance 2.0的基準測試表現雖紮實,但更多圍繞實際產品應用場景展開。
這讓HappyHorse非常適合進行前沿測試的人員,而Seedance 2.0則更適合那些尋求定位更清晰、獲得官方支持的模型的團隊。
如果你想要簡要版的內容,HappyHorse作為前沿級訊號顯得更亮眼,而Seedance 2.0從官方資料來看則更易於評估。這意味著HappyHorse或許更適合激進式測試,但在工作流程對話中,Seedance 2.0依然更容易被證明合理。
《HappyHorse》為何備受關注
HappyHorse 憑藉公開榜單與黑馬勢頭闖入大眾討論,因此獲得了大量關注。這種首次亮相讓人們不禁發問:該模型究竟只是紙面表現亮眼,還是在創作者所關注的兩兩對比場景中確實更勝一籌?
它還通過其公開的模型卡片語言展現了開源特質,這讓它對建構者以及熱衷於鑽研技術的團隊來說更具實際意義。
Seedance 2.0 何處的工作流程敘事更清晰
Seedance 2.0 具備更清晰易懂的官方敘事優勢。字節跳動將該模型闡釋為多模態音視頻生成與編輯框架的組成部分,而非讓讀者只能通過排行榜與社區總結來自行揣摩其價值。
對於以參考為優先的工作流程,採用靜圖轉動態的工作方式比從零開始重新處理整個場景要合理得多。
這種差異在生產環境中至關重要。清晰的公開框架能讓模型在規劃、採購、內部演示和團隊採納等環節更易於評估。
這對創作者和團隊意味著什麼
追求頂尖動作品質的獨立創作者可能更容易被HappyHorse吸引。需要對模型如何適配腳本、參考素材、音效及動作效果給出統一解釋的團隊,或許仍更傾向於將Seedance 2.0作為更穩妥的對照參考點。
對於不希望整個工作流水線依賴某一款熱門模型的團隊來說,Elser AI 是更穩妥的錨點。
選擇HappyHorse用於前沿對比與品質優先的測試
選擇 Seedance 2.0,以獲得更清晰的產品架構及多模態工作流程邏輯
將兩者都視為更廣泛工作流水線的組成部分,而非將其當作一個可一鍵完成的完整工作室
為何這項對比比看起來更難
HappyHorse vs Seedance 2.0 表面上聽起來很簡單,但大多數讀者實際上是在同時對比至少四種不同的要素:原始輸出品質、可重複性、公開文件,以及該模型融入工作流程的難易程度。這就是為什麼頭條上的相關評價往往不像乍看之下那麼有用。一款模型可能在某條爆款短視訊片段中表現得更亮眼,但在實際生產中卻依然遜色,因為它更難被調控、更難被接入,或是更難向團隊解釋清楚。
這種複雜性在公開資訊分布不均衡的市場中尤為關鍵。HappyHorse與Seedance 2.0的評判依據並不處於同一證據層級。一方可能擁有更充分的官方資料,而另一方則可能擁有更亮眼的標竿熱度或更高的社群關注度。有意義的對比必須釐清這些不同的維度,而非將它們一概歸為一個模糊的「哪個更好?」的答案。
公平測試應衡量的內容
公平的測試應當從真正創造價值的任務開始。對於以模型為核心的創作者工作而言,這意味著必須檢查提示詞遵從度、視覺一致性、可編輯性,以及生成結果經過多次重新執行後是否不會失效崩潰。團隊還應該測試每個選項在不同類型的請求下處理同一提示詞包的難易程度,而非讓每個模型只在其擅長的場景中大放異彩。
它也有助於採用一套簡單的評估標準:首輪實用性、一般場景下的輸出、故障後的復原能力,以及將結果整合到流程管線其餘部分所需的工作量。事實上,這些衡量標準通常比公開吹噓的本錢更為重要,因為它們能讓你知道該模型是真正減少了工作量,還是僅僅將工作轉移到了後續的清理階段。
更佳的選擇因場景而異
當你從抽象對比轉向實際應用場景時,HappyHorse與Seedance 2.0的更佳選擇會發生變化。追求打造亮眼樣本的獨立創作者,與需要穩定可控表現的工作室,可能會做出不同選擇。注重研究的開發者可能更在意模型開放性或實驗操作空間,而代理商則更關注審批速度、可解釋性以及版權保障信心。
這就是為什麼合理的評估結論始終都應該是有條件的。在快速社交影片測試中表現最優的模型,未必是你會圍繞其搭建內部工作流程的那款。同樣,倘若你的工作是搶在所有人之前發掘下一個視覺性能天花板,那麼那些在上線審核中看起來更穩妥的模型,也並非你會選擇的那款。
團隊在比較模型時常忽略的內容
團隊往往會忽略進行比較時的週邊成本。真正的問題不僅在於哪個模型更強大,更在於哪個模型生成的決策更易於落地實施。如果兩個系統的視覺品質不相上下,那麼具備更清晰的部署流程、更完備的文件支援或更適配工作流程的那個系統,依然是更明智的選擇。當多個利害關係人需要信任整個流程,而非僅認可最佳樣本輸出時,這一點尤為如此。
另一個常見迷思是僅比較最終輸出結果,卻忽略了其生成路徑。提示詞負擔、重試次數、場景可控性與編輯可預測性,都會影響模型長期的實用表現。這些細節雖然不像並排對比的截圖那般鮮光亮眼,但往往正是這些細節決定了,在首發熱度消退後,這款工具能否站穩腳跟。
什麼會改變判決結果
HappyHorse訴Seedance 2.0一案的判決應被視為臨時生效而非終局裁決。更便捷的取得管道、更清晰的文件資料、更充分的價格透明度,或是更廣泛的公開測試,都可能迅速扭轉當前態勢。正因為如此,最具說服力的比較分析會明確指出判決結論可能發生變動的情形,而非假裝市場早已塵埃落定。
對於大多數讀者而言,最明智的做法是讓結論保持務實:結合自身實際任務評估模型,保留穩定的配套工作流程,並隨著公開記錄的完善重新審視這項決策。 這種方法既能幫你避免對炒作過度反應,也能避免對有意義的變化反應不足。
底線
HappyHorse 與 Seedance 2.0 的對比,本質上是發展勢頭與清晰性之間的較量。就目前而言,HappyHorse 或許是更能勾起純粹好奇心的那款,但如果你的後續疑問是團隊日常實際該如何使用該模型,那麼 Seedance 2.0 依然更易被理清邏輯、推演使用方式。