如何用AI製作30秒動畫短片:實用新手入門工作流程
三十秒聽起來一下子就過了,但當你試著撐滿這三十秒時,就會發現沒那麼簡單。
它夠長,可以介紹角色、設定問題、帶來反轉,並以令人難忘的畫面收尾。同時它又夠短,讓獨立创作者可以完成作品,不會陷入無止境的製作當中無法自拔。
那讓一支30秒的動畫短片成為最佳的首批之一 人工智慧動畫 專案。
大多數新手常犯的錯誤,就是在還沒決定影片劇情前,就先打開影片產生器。他們先產生一支美美的片段,接著又做另一支,最後才發現這些鏡頭根本不屬於同一個故事。
更完善的流程始於架構。在本指南中,我們將透過六個鏡頭、一個核心角色、一個拍攝地點以及一項單純的情緒轉變,打造一支完整的短片。
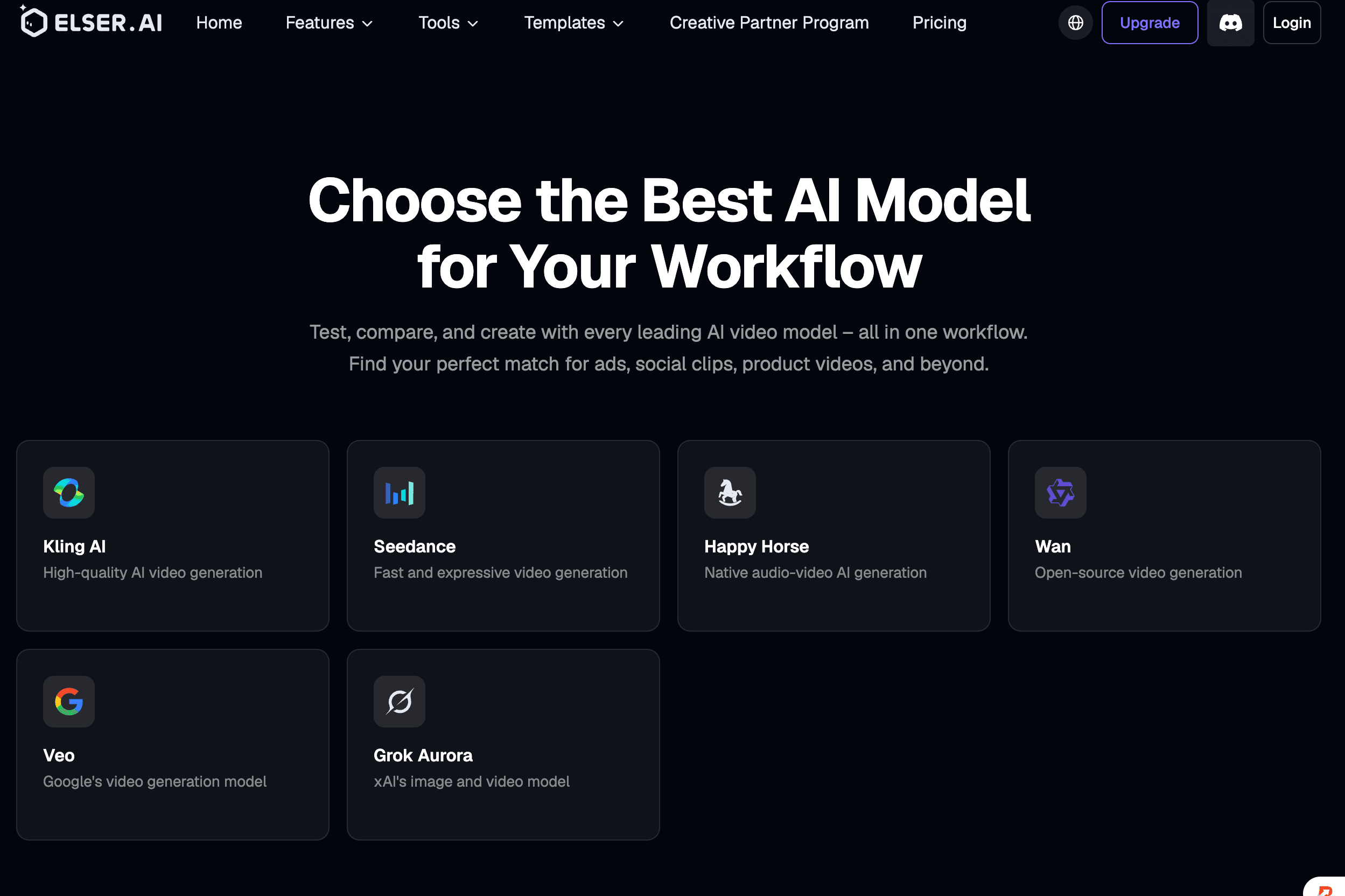
Elser AI 特別適用於此工作流程,因為它整合了腳本生成、角色設計、故事分鏡、動畫、配音、音樂、音效與唇形同步功能。其動畫工具的設計理念是從點子一路打造完整故事,而非僅製作單一段短片就停止。
我們正在創作的故事
以下是這個概念:
一位年輕的送貨女巫冒著雨在城市裡疾馳,要送一個神秘包裹。 她遲到了,打開門後,才發現那個包裹竟是給她的生日蛋糕。
它有一個主角、一個目標、一個障礙,以及一次情感反轉。最重要的是,不需要一段鋪陳就能理解它。
我們的時間軸:
時間 劇情節點
0–4 seconds 營造這座多雨的城市
4–9 秒 介紹女巫與包裹
9–14秒 顯示緊急航班
14–19秒 她抵達目的地
19–25 秒 門打開,緊張氣氛暫停
25–30 秒 生日驚喜揭曉與反應
那已經足夠開始規劃了。
步驟1:為螢幕撰寫,而非背後故事
短片是由可見的動作所構成的。「她感到孤獨,因為沒有人記得她的生日」這句話對編劇來說相當實用,但無法直接被拍攝下來。
將那個想法轉化為看得見的事物:
她查看她靜音的手機。
- 她看見裡面有生日橫幅。
她緊繃的肩膀垂了下來。
她強忍著眼淚,同時露出微笑。
針對一支30秒的AI動畫短片,請撰寫不超過六個劇情節拍。每個節拍皆需包含一個主要動作。
一段可正常運作的微型腳本看起來就像這樣:
鏡頭1:雨落在霓虹城市的上空。一個小型飛行身影漸漸靠近。
鏡頭2:身穿黃色雨衣的年輕女巫米娜,騎著掃帚時緊握著一個蛋糕大小的包裹。
第3鏡頭:風將她往旁邊推。她護住包裹,快速穿梭在建築物之間。
鏡頭4:米娜降落在一間溫暖公寓外,渾身濕透且氣喘吁吁。
第5鏡頭:門打開了。朋友們大喊:「驚喜!」
鏡頭6:米娜看著包裹,發現這是給她的,並笑了出來。
劇本很簡單,因為畫面承擔了所有重任。
步驟2:建立模型能夠記住的角色
複雜的設計並不永遠都是好設計。
人工智慧影片模型 比起佈滿細小裝飾的形象,更能保留具備清晰輪廓、調控合宜的配色,以及少數獨特特徵的形象。
為 Mina,定義:
- 短的深紫色頭髮
- 琥珀色眼眸
黃色連帽雨衣
- 深藍色洋裝
- 棕色及踝短靴
紅色外送側背包
小型木製掃帚
黃色外套與紅色側背包提供了兩個易於辨識的視覺錨點。避免在這段短片期間更動它們。
建立正面人像、四分之三人像與全身人像參考資料。保持表情中性,並確保服裝沒有被遮擋。請先核准設計再生成場景。
Elser AI 以角色為核心的工作流程,讓創作者建立原創角色(OC),並可在故事板與影片製作中重複使用該角色,無需每次都在提示詞中重新建構該角色的設定。
步驟3:在使用影片點數前先製作分鏡腳本
一份分鏡稿 並非裝飾性的前置作業。 這是你能以低廉代價及早發現代價高昂的錯誤之處。
為每個鏡頭建立一個面板並進行檢查:
米娜在每個畫格都認得出來嗎?
這間公寓是否出現在正確的那一側?
- 包裹永遠都是一樣的尺寸嗎?
雨會合乎邏輯地持續下去嗎?
鏡頭尺寸是否有所不同?
- 觀眾能理解這個驚喜嗎?
Elser AI 的分鏡工作室可將劇本或場景描述轉換為分鏡版面、鏡頭建議、拍攝角度與視覺導向。(動畫與影視製作)
一個實用的拍攝鏡頭模式是:
1. 寬景定場鏡頭
2. 中等角色介紹
3. 動態跟拍鏡頭
4. 全身落地鏡頭
5. 過肩揭露
6. 特寫反應
這會創造視覺節奏。連續六個特寫鏡頭會讓城市與動作顯得異常渺小。
步驟4:產生已核准的靜態畫格
在動畫製作前,為每個鏡頭產生關鍵畫面。
這是提升角色一致性最有效的方法之一。 靜止畫面能讓你有時間調整臉部、服裝、構圖與場景,不用同時擔心動態的問題。
使用一致的提示詞框架:
[鏡頭尺寸與攝影機] + [鎖定的角色描述] + [動作] + [地點] + [燈光與天氣] + [動漫風格] + [連續性限制]
範例:
中景跟拍鏡頭拍攝米娜——一名留著深紫色短髮、琥珀色雙眼的年輕女巫,穿著同款黃色連帽雨衣,背著紅色外送側背包,騎著小型木製掃帚,同時護著一個方形包裹。雨夜霓虹城市夜景,藍色與洋紅色的反射光影,手繪2D動畫風格,乾淨俐落的輪廓,平面賽璐璐著色,面部造型穩定一致,無服裝變化。
「same」一詞僅在模型具備實際參考依據時才有用。請附上米娜核准的角色圖片,而非指望模型能記住先前的提示詞。
步驟5:針對每一次拍攝選擇合適的模型
你不需要在全部六次拍攝中使用相同的模型。
針對這支短片:
- 使用 Veo 拍攝這段雨中城市的建立鏡頭。
- 使用 Kling 來控制掃帚的移動與著陸。
- 若你有動態、音樂或視覺參考素材需要結合,請使用 Seedance。
- 使用受控的圖像轉影片模式來處理最終的面部反應。
Seedance 2.0 支援文字、圖片、影片以及音訊參考素材。Kling 3.0 強調多鏡頭敘事與元素一致性。Veo 3.1 提供攝影機控制、首末格引導、場景延伸以及搭配音訊的影片。(seed.bytedance.com)
裡面 Elser AI,此種模型選擇將成為單一專案的一部分,而非三個獨立的訂閱方案與檔案系統。
步驟6:一次只為單一動作製作動畫
影片提示詞應描述鏡頭拍攝期間的變化。
請勿重複輸入影像中已有的所有視覺細節。請專注於動態:
鏡頭跟在米娜身旁,跟隨她向前飛行。強風輕輕將她推向右側;她順勢傾身,並用雙臂緊緊抱住包裹。雨斜斜飄落。頭髮與外套隨之自然飄動。臉部、服裝、包裹及掃帚請保持不變。
那個提示詞將移動與身分區分開來。
對於一個五秒的鏡頭,通常一個角色動作和一次鏡頭動作就足夠了。「她飛翔、轉身、揮手、丟下包裹、再接住、潛入,並對著鏡頭微笑」這並非雄心壯志,只不過是六次失敗的機會。
將重要的鏡頭動作遠離剪輯切點。留給畫面動作半秒的時間啟動並穩定下來。如此一來剪輯工作會變得輕鬆許多。
步驟7:於唇形同步前錄製語音
我們的短片只需要一個有台詞的片刻:
「等一下…這是給我的嗎?」
在套用唇形同步效果之前,請先錄製或生成台詞。演出內容決定時序,因此影像應遵循已核准的音軌,而非強行將對白塞進預先設定的時長內。
適合用於唇同步的優秀台詞應具備:
- 清晰音訊
- 輕微背景雜音
- 自然節奏
- 前或後的短暫停頓
- 清晰的情緒,不帶誇張的速度
Elser AI combines voice cloning and lip sync with its animation workflow. This allows creators to establish a recurring character voice and synchronize it with the visual scene. (elser.ai)
只針對 Mina 說話的特寫鏡頭進行口型同步。 朋友們可以在畫外大喊。 如此一來不僅能節省運算處理量,還可避免要求模型一次同步多張小臉孔。
步驟 8:於圖層中新增音樂與音效
聲音讓短片給人的感受時長比其實際播放時間更長。
使用四層:
1. 氛圍:雨與遠處的車流
2. 動作:掃帚衝刺與外套飄揚
3. 劇情特效:降落、開門、派對彩炮
4. 音樂:緊張的節奏轉變為溫暖的生日主題
不要把所有聲音都調得過於響亮。對白必須保持清晰可聞,而驚喜感也需要有空間發揮效果。
音樂應該在揭曉時改變。即便只是簡單的和聲轉換,也能告訴觀眾情感意義已經改變。
Elser AI內建音樂與音效生成功能,讓創作者可以在製作動畫的同時,產生風、雨、腳步聲、門聲以及其他符合場景需求的音效。
步驟9:編輯以確保清晰度,而非追求最快速度
三十秒不需要慌亂的剪輯。
靜音觀看這部電影。倘若劇情模糊不清,音樂也無法讓這段故事變得通順。 接著不看畫面只聆聽聲音。如果缺少情感轉折,就調整配樂與音效。
第一個實用的編輯動作可能是:
- 鏡頭1:3.5秒
- 鏡頭2:4.5秒
- 鏡頭3:5秒
- 鏡頭4:4秒
- 鏡頭5:5秒
- 鏡頭6:8秒
這個反應獲得最多的時間,因為它承載了這部電影的意涵。
盡量依照動作進行剪接。如果米娜向右飛出畫面,則下一個鏡頭以同方向持續的動作開場。這個小小的連貫性安排,能讓各獨立的AI鏡頭片段看起來像是刻意串接在一起的。
步驟10:執行導通檢查
匯出前,請逐格檢查這段短片。
查看 Mina 的:
- 臉部與外表年齡
- 頭髮長度與顏色
- 外套設計
- 背包位置
- 身體比例
- 掃把形狀
- 語音
然後檢視這個世界:
- 降雨方向
- 一天中的時間
- 燈光顏色
- 公寓外觀
- 包裹尺寸
- 螢幕方向
僅重新產生受損的鏡頭畫面。請勿僅因某個配件變色,就替換正常運作的影片序列。
常見錯誤
從影片生成開始:
先修正劇本、角色與分鏡腳本。
僅使用純文字針對重複出現的字元:
將已核准的參考資料附加至每個重要的世代。
將對白放入全景鏡頭畫面中:
當唇部動作為重點時,請使用中景鏡頭與特寫鏡頭。
讓每一鏡頭都充滿戲劇張力:
一部電影需要較平靜的鏡頭,如此一來高潮部分才會顯得有意義。
變更沒有視覺規則的模型:
保持相同的角色參考、配色、長寬比與風格提示詞。
未經許可使用受版權保護的字元:
創造原創角色,或使用您獲得授權可改編的素材。
最終結果
一支優秀的30秒動畫短片,不需要複雜的神話設定或是十個場景。它只需要一個鮮明易懂的角色、一個明確的願望、一次轉變,以及一個值得牢記的最終畫面。
這項技術可以生成畫格、動作、語音、音樂與特效。你的工作是決定每個鏡頭的涵義。
這就是創作者與AI動畫平台之間的實用合作關係:工具負責處理製作的複雜性,而創作者則仍舊需對創作立意負責。